This is a manual for semiclassical agile estimating. It explains every rule and presents every calculation required to use the methodology. It is free and will remain free. However, it is not intended to be a instructional document. It does not explain how this technique meshes with other agile techniques. There are no case studies. It does not explain how it might be implemented.
Introduction
- Semiclassical Estimating for Agile Projects
- Overview of Semiclassical Estimating
- Concepts and Capabilities of Function Point Estimating of Initial User Stories
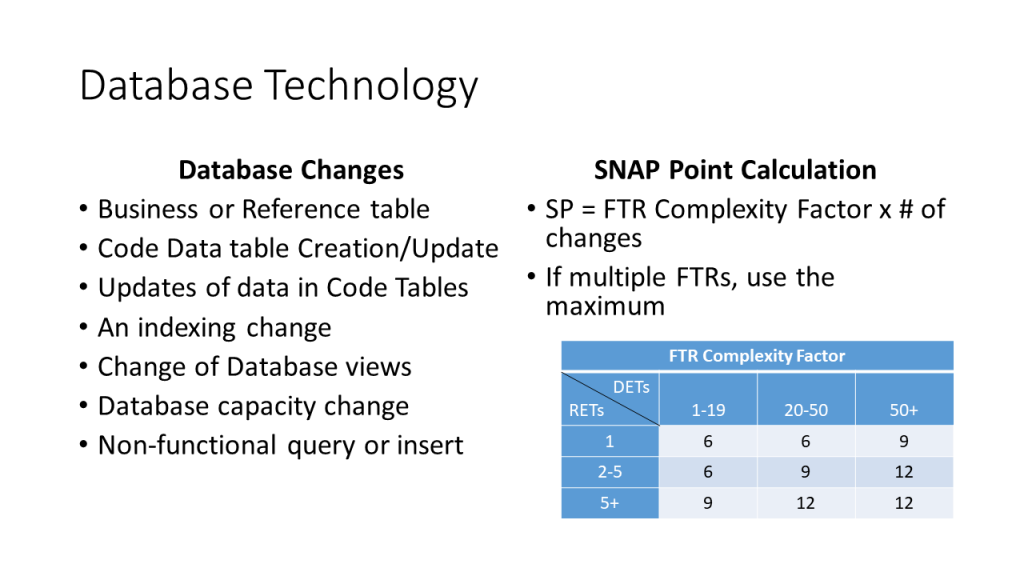
- Concepts and Capabilities of SNAP to Size Changes Between Releases
- Use the COCOMO Suite to Estimate Staffing and Schedule for Agile Projects
Set Up for Sizing
- Draft Scope and Boundary
- Identify Locations
- Identify Roles
- Identify Partitions
- Identify Code Tables
- Counting Batch Processes
Size New Processes and Data Groups
- Adding an Input Screen
- Adding an Output Screen
- Adding an Elementary Process
- Adding Data Groups
- Add a Typical Process
- Add a General or Marco Process
- Calculating the Size of the First Release
Estimate and Schedule the First Release
- Transforming Size into Schedule and Effort
- Cost Drivers – Scale Factors
- Cost Drivers – Effort Multipliers
- Using COPSEMO and CORADMO on Agile Projects
- Transforming Schedule and Effort into a Plan