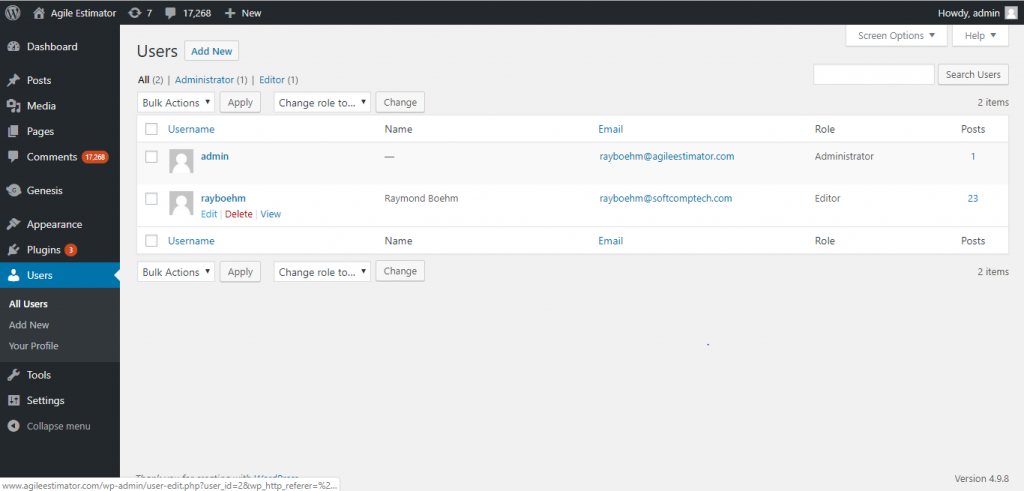
There are certain constructions that occur frequently when systems are developed. Some people refer to these as patterns or templates. The screen above is an example from WordPress. It lists the users of a web site. There is an ability to select a subset of the users by using the Search Users field and button. This is basically part of the list functionality. There is an Add New button which allows a new user to be created. If you put your cursor over one of the entities in the list, for example rayboehm, WordPress displays the commands that you could enter for this entity. You can edit the entity. You can delete the entity. You can also view the entity. The view functionality is actually used alone, as well as to provide the current data as part of the edit functionality.
Roberto Meli analyzed a corpus of function point counts and saw this pattern. He called it a typical process. He identified three sizes for typical processes. The medium size has the CRUD processes and a list which is normally an External Inquiry (EQ). The illustration above is an External Output (EO) not an EQ. You can see this because it displays the number of posts that each user has made. This is still a medium size typical process. For one thing, it is closest to average. For it to be large there would have to be both a list (EQ) and a report (EO). In addition, when estimating in an agile project, the data fields associated with a process are usually not defined yet. It would only be when this report was being implemented, would a discussion occur with the user and the total number of post fields would be requested. That information would not have been available at the time of the estimate. If there had been no list, then the user would have had to know the Username and enter it to bring up the information on that user. That would essentially be the Read functionality of CRUD. Update and Delete would probably be available on that screen. There would probably be a Create button or menu item somewhere. This would be a small typical process. Once the size has been established, use the function points listed in the table below as an estimate.

Some people are concerned that they are getting too rough an estimate from this because it does not consider the number of Data Element Types (DETs) or File Types Referenced (FTRs). The estimate is not too rough. Early in the life cycle you probably do not know how many DETs and FTRs are involved anyway. Even if you did, the time that you save using a template like this can be more productively applied to other estimating, planning and management activities.
Function points are technology independent. It should be possible to use this template for other data feeds. It usually does not work. Data feeds often have Create, Update and Delete functionality. The Read is usually a read associated with the Update, but it does not correspond to a separate EQ. Furthermore, some transaction files have more functionality than just create, update and delete. A securities data feed might have transactions for stock splits, stock dividends and many other processes. It is best to reserve the typical processes for the types of screen functions that were described here.
Leave a Reply