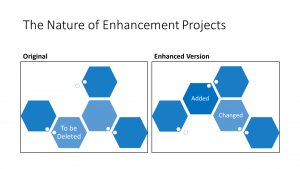
The concept of new development is pretty straight forward. You start with nothing, write some code and then you have an application. Enhancement projects are a little more complicated. You start with an existing application. You add to it. You may change some of the existing code. You may even delete some of the original application. At the end, you have an enhanced application. For example, suppose that you had an application that evaluated the probability of a financial instrument changing in value, i.e. going up or down. You would have some screens, some interfaces and probably some data that was maintained. One of the pieces of data that you used was the amount of change that that instrument would go through in an average day. Let us suppose that you had to maintain that piece of information and store it in the application. Then you found that the information was available and could be accessed by the application directly. The enhancement would consists of an added interface to the information. There would probably be changes in the screen logic to utilize the new information from the interface. Finally, you would delete the screens and database that you had used to store your hand entered version of the data.
What just happened? Was this a change to a application that was in production, or was this one of the iterations in an agile development project. There is often the need for an existing application to be modified. This is sometimes called adaptive maintenance. Adaptive maintenance allows an application to be changed so that it adapts to new needs by its users. Corrective maintenance is primarily to fix bugs that have shipped or gone into production with the application. Perfective maintenance is closely related to corrective maintenance, but it is performed before the defects manifest themselves. The effort required for these type of maintenance are often not estimated at all. Preventative maintenance is similar in that it usually addresses things that are not functional, like optimization. However, it is time that we start to estimate this type of activity. The same is true of conversion maintenance. Some people consider it a non-functional form of adaptive maintenance because there is no change in functionality. Again, these technical projects need to be estimated and planned.
Agile development involves applications being developed in iterations. In scrum, these iterations are called sprints, other approaches have different names. Some of these iterations become releases. They are released to the user community where they are utilized. This is consistent with the values and principles of agile development. Agile developers embrace change, and it is when an application is being used that people see the types of changes that would improve it. These releases are so important that agile developers will often create stubs and later refactor code in order to deliver these releases. In other words, they will create a release that requires them to change and delete existing code. Traditional developers tend to hate change. They want to develop specifications and implement them without worrying about users making changes. They see changes as something that simply slows down the development process. I had one situation that was even more complicated than that. We were estimating and planning a large system for a utility. I suggested that we would be able to plan the development with three releases that would allow the system to be returning value to the client more quickly. There was no real cost for this. Looked at above, each enhancement had no changes or deletions, just added functionality from release to release. The sponsor said no. When I asked why, he explained that if we implemented one-third of his system, his management might feel that it was enough for now and pull the rest of his funding. If they had nothing to show until the end, then it would be funded until the end. An exception to traditional developers hating change is contract programming organizations who have built change management into their software development life cycles. They can negotiate changes through the process and turn a 2 million dollar project into 2.5 million dollars thanks to the changes.
I brought up this point about 10 years ago when I was exploring agile estimation as a thesis topic. At the time, my colleagues felt it was an important nuance and a distraction from any attempt to do agile development. I went on to develop an approach to estimating agile projects like they were simply new development. It seems to work for the development as a whole. Late last year, I came across a journal article written by Anandi Hira and Barry Boehm of the University of Southern California. The article was titled “Using Software Non-Functional Assessment Process to Complement Function Points for Software Maintenance.” I did not include a hyperlink because access to the article requires an ACM membership and possibly access to their digital library. However, the conclusions of the study are straight forward and, to me, surprising. When looking at projects that simply added functionality, such as new system development, it appeared that function points alone would yield worthwhile predictions. Using Software Non-Functional Assessment Process (SNAP) along with the function points yielded better estimates. When looking at projects that changed functionality, such as enhancement projects, SNAP yielded worthwhile estimates. Using function points with SNAP points did not improve or worsen the estimate. Hira and Boehm suggest that you use both measures in both situations for consistency.
In the beginning of the post it was mentioned that enhancement projects consisted of adds, changes and deletes. However, there was no mention of what was being added, changed or deleted. There could be many answers that question. Three common answers are lines of code, function points and SNAP points. Each has been used and each has its problems.
Using lines of code to measure enhancement size has all of the problems it had for new development work. In addition, it is necessary to segregate the counts for number of lines added, changed and deleted. You do not truly know what the lines of code count is until after the project is done. Then you do not need the estimate. Even then, there is no standard way to count lines of code. Is it a statement in the programming language being counted? Is it a physical line? Do you count comments? Do you count declarative statements? Once you have made these decisions, how do you combine your adds, changes and deletes. Is the size simply the sum of the three values. In other words, if I added 100 SLOC, changed 100 SLOC and deleted 100 SLOC is the total enhancement to 300 lines of code. That is possible. Some organizations have percentages that they apply to add, change and delete. For example, they might feel that the adds contribute 100% to the size of the enhancement, while the changes and deletes contribute 40% and 5%, respectively. In the example, the lines of code would combine to be 145 lines of code. In COCOMO II, there is a maintenance size that is basically a Maintenance Adjustment Factor times the sum of size added and size modified. Size deleted is ignored. The sizes can be in thousands of source lines of code (KSLOC), Application Points (a COCOMO II measure that is an alternative to either KSLOC or Function Points) or Function Points. By the way, the COCOMO II team mentioned that they get their best results from KSLOC. A minor change to a report (application points) or an External Output (function points) may overstate an estimate. The Maintenance Adjustment Factor to weight the effect of poorly or well written software on the maintenance effort. It appears that This measure may be getting into that gray area between size measurement and effort estimation with cost drivers. However the COCOMO II team refers to this as size, so we might as well do the same.
There are several forms of function points, including IFPUG, COSMIC and Mk II. The one maintained by the International Function Point Users Group (IFPUG) is the most widely used. IFPUG maintains the Counting Practices Manual (CPM), administers tests to certify function point specialists and to certify classes and tools. The CPM explains exactly how the enhancement count should be calculated. Basically, it is the sum of the functions that are added, changed and deleted. People who have spent too much time reading the CPM will be quick to correct this statement. For one thing, the enhancement count also includes the functionality associated with conversion. Seasoned estimators know that the conversion portion of a project is tricky to estimate. It is often performed by a separate team, for example, the legacy programmers who understand any previous system and the data files that it used. Thus, it is often estimated separately. Another thing that function point specialists may point out is that the above formula did not take into account the Value Adjustment Factor before and after the enhancement. Theoretically this is part of the calculation. However, most estimators are getting away from using the adjusted function point count in favor of the unadjusted count without a Value Adjustment Factor. The unadjusted function point count is what COCOMO II expects as its size driver. There remains one critical issue in the minds of many estimators: developing a new report, making a change to an existing report and deleting a report all have the same function point count. However, most people believe that they have different amounts of effort associated with them.
In 2009, IFPUG delivered its first draft of the Software Non-functional Assessment Process (SNAP). Considering non-functional requirements when estimating was not a new idea. The function point Value Adjustment Factor (VAF) had been meant to quantify these non-functional requirements. There seemed to be agreement that it was inadequate to capture the extent to which these non-functional requirements might impact the size of a piece of software. Cost drivers in the macro (top-down) estimating models where the next attempt. Of course, these were tied to the models in question. SNAP was a more general way to assess the amount of non-functional requirements for a software development or enhancement project. The size of an non-functional requirements of an enhancement project are the sum of the SNAP points added, the SNAP points change and the SNAP points deleted. This seems like it would lead to the same concerns as function points. However, the COCOMO II team had not seen SNAP points before they published COCOMO II. Likewise, the industry does not have enough experience with SNAP yet to worry about this. The paper by Hira and Boehm is the first quantitative study that I have seen to address this. As stated earlier, they state that SNAP can be used to predict enhancement projects better than function points do.
What is the next step for estimators? Any estimator who is using function points should become familiar with SNAP. It has the potential of improving estimates for new development. It may be the only way to get worthwhile estimates for enhancement projects. The question becomes how to incorporate this into the remainder of the estimating process at your organization. The first difficulty is transforming SNAP points into lines of code. That problem was solved for function points and is the basis for how algorithmic models like COCOMO work. A way for incorporate SNAP points might need to be found. The second difficulty is reconciling SNAP points with the models cost drivers. This is far from trivial. Some cost drivers tend to be more size related, others tend to impact the difficulty of code development without really impacting the size. To make things worse, the decisions that are made for COCOMO II will be different than the decisions that might be made for SEER-SEM or other models. Why go to the trouble. SNAP is probably the only way to reliably estimate the schedule and estimate for the next release. As an added benefit, it may improve the estimate for the entire project.