
The above is an overview of the semi-classical estimating process. The process is fueled by the initial user stories. Conceptually, the result is a burn down chart that will show how many iterations will be required for the next release. The required team size is also predicted.
At this high level, it looks like semi-classical estimating does the same thing that modern agile estimating techniques. However, it does it in a completely different way. It can be used in situations where agile techniques alone are not possible. For example, the modern agile estimating approach relies heavily on estimates provided by the development team. However, there are times when an estimate is necessary before the technical team has been assembled. Without a technical team, the use of techniques like planning poker are not possible. However, the semi-classical approach outlined here can still be used. An independent estimator or a product owner can develop the estimates using semi-classical estimating.
Even when the technical team is available and an estimate has been made using the typical agile approach, this semi-classical estimating can give an orthogonal estimate. It is independent of the one that is done by the agile team. Often, estimates done by the development team can be flawed. Before agile development, estimates were often done by project managers. They were trained in estimation and were often good at it. They were also trained negotiators and were often good at that to. They often turned their estimates into negotiations for more resources. They could not lose. If they took longer than they thought they would, they had already negotiated a contingency. If they finished early, they appeared to be heroes by bringing in the project under budget. This mentality can rear its head with development teams today.
The reverse phenomena can also occur. Several years ago a project team was scheduled to go into user acceptance test in another week. The executive management of the software development firm was uneasy about the situation. I was sent to see what was happening. I interviewed a variety of developers. I spoke to one in particular that I had known over the years. He was smart and I was sure he would tell me the truth. I asked him about the functionality that his group was developing. He was having trouble explaining it. He then said, “it is too bad you cannot stay until next week. We are going into user acceptance testing and I could show it to you.” He was not stupid and he was not lying. He was the victim of groupthink. I knew that the project was about a year away from completion. The client canceled the job after a few more months.
An independent estimator or a product owner with training in semi-classical estimating would be able to generate an estimate. Either of these people could estimate independently from the agile team. They should be immune to the biases described above. Their estimate and the agile team’s estimate could be compared in an effort to get to the best estimate.

The picture above is of the Large Hadron Collider. It was built by the European Organization for Nuclear Reserarch, also known as CERN. It is a 17 mile circle of magnets that are designed to accelerate subatomic particles, including parts of hadrons, in an effort to discover other subatomic particles and to understand the very nature of reality itself. Accelerators used to be called atom smashers because they were used to break atoms into their subatomic particles. We all studied protons, electrons and neutrons in school. However, the atom is composed of a menagerie of particles including quarks, photons, neutrinos and the Higgs boson.
In semi-classical estimating, the first thing to be done is to smash the user stories into sub stories. Agile developers are taught to INVEST (Independent, Negotiable, Valuable, Estimatable, Small and Testable) in good user stories. Semi-classical estimators know that these user stories are seldom estimatable in themselves. Even a small simple story like, “As a sales manager, I can input a salesperson profile” has at least two sub stories associated with it: an elementary process to input a salesperson profile and a logical file of salesperson information. Just like subatomic particles, our identification of sub stories is evolving. Certain types of processes, like maintenance screens, are sub stories. Many types of sub stories have already been identified. It is likely that different problem domains will eventually have their own sub stories. These will be templates that are constantly being used and eventually will be recognized as templates or patterns for estimating purposes. In the meantime, elementary processes are a type of sub story that can be used in combination to represent the other functional sub story. For example, if maintenance screens were not identified as sub stories, they could have been represented as 4 elementary processes: add, change, delete and an implied inquiry.
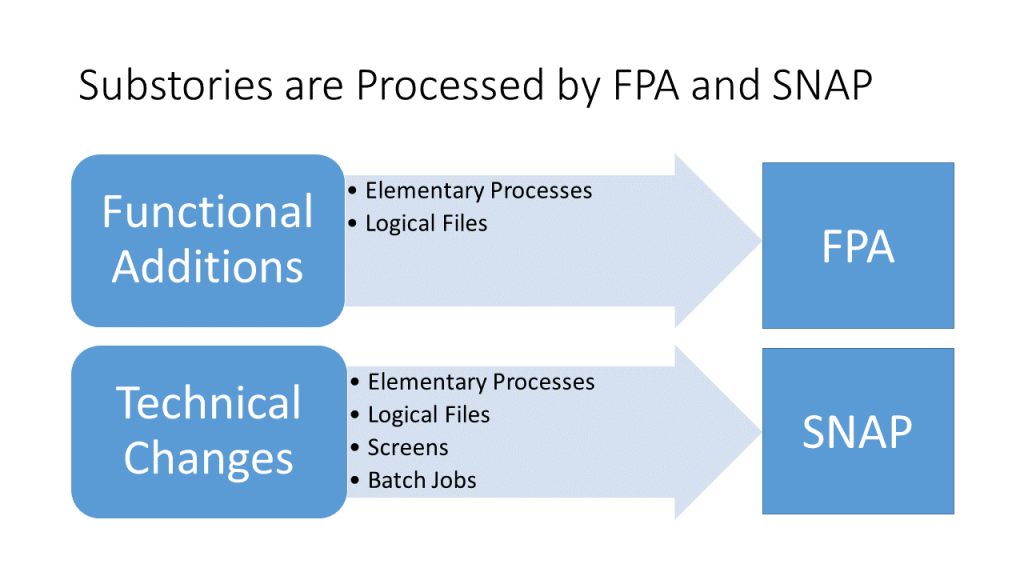
Function Point Analysis has been with us since the seventies. It was a technique designed to estimate software development time. At that time, software projects were usually produced in a big bang. Suppose that you had a 2,000 function point application to develop. This was large, bordering on huge. Still, lots of these projects were done. About 10% of new software development projects fell into this range. A project like this would probably be estimated to take a calendar year. Using a waterfall approach, team size would vary. About 10 people might be involved in analysis, but the team might ramp up to 30 people when the coding phase began. In any case, there was no workable system available until the year was up. Function points worked fine for this, but this is not the way software is developed today.
Using an agile development approach, this same project might be delivered in five releases. The first would be expected in a couple of months. It might have only 300 function points of the eventual functionality. However, it might be estimated in a manner very similar to the one above. However, estimating the next release is not as simple. The next release involves new functionality. It also involves changing functionality that was added in the last release. Simplified versions of some screens, interfaces and files may have been implemented in the first release because it was “the simplest thing that could possibly work.” There have been some issues with using function points to estimate these changes.
In 2007, the International Function Point Users Group (IFPUG) approved the creation of a Software Non-functional Assessment Process (SNAP). It was intended to measure the technical (non-functional) aspects of software requirements. Between it and function points, it was hoped that better estimates of software development effort could be made. This has happened, but not in the manner that some people expected. It turns out that SNAP was a good predictor of the effort involved in software modifications. In semi-classical estimating, a somewhat enriched form of SNAP is used to estimate the changes that will naturally occur as the development team moves from one application release to the next.
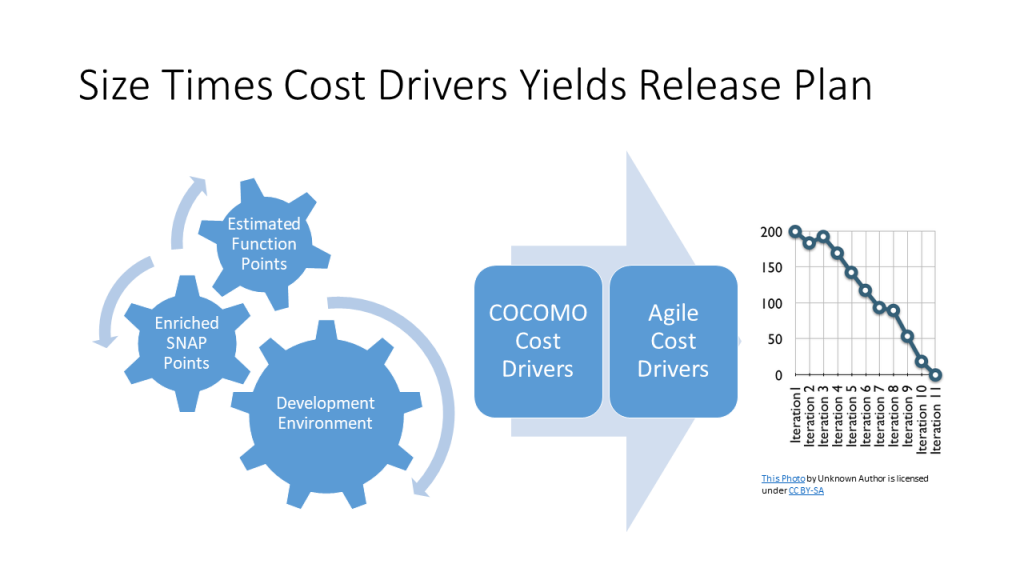
The estimated function points and enriched SNAP points together make up the consumer size of the application being developed. It is a driver of the effort required to produce the software, but it is incomplete. The development environment must be considered. Different development environments have different gearing factors. When data processing began, many applications were written in Basic Assembler Language (BAL). BAL programmers had to decide where in storage their data would reside. They had to move them to computer registers before they could perform operations like addition on them. Programming was a laborious process, far removed from the business problem that was being solved. After some time, the COmmon Business Oriented Language (COBOL) was developed. An expression like “ADD A to B” was all that was required to add two numbers. The programmer did not have to consider what was in the registers or where they were in memory. COBOL programmers expanded less effort to solve the same problem than BAL programmers did. Some people would say that COBOL was more highly geared than BAL. Another way to look at this was that for the same consumer sized application the one developed in COBOL had a smaller producer size.
In the eighties, Barry Boehm (no relation to Ray Boehm) published Software Engineering Economics which introduced the COnstructive COst MOdel (COCOMO). It was actually a set of models that were useful in estimating the effort and schedule for software development. They were primarily driven by source lines of code (SLOC), but with software development environments like Excel, the concept of a line of code started to lose meaning. Producer size is a more relevant way to think of this. Since that time, a COCOMO II has been released along with several other related tools in the COCOMO suite. Some are more relevant to agile development than others. In any case, the objective is to establish the team size and how many months it will take to develop the next application software release.
Leave a Reply