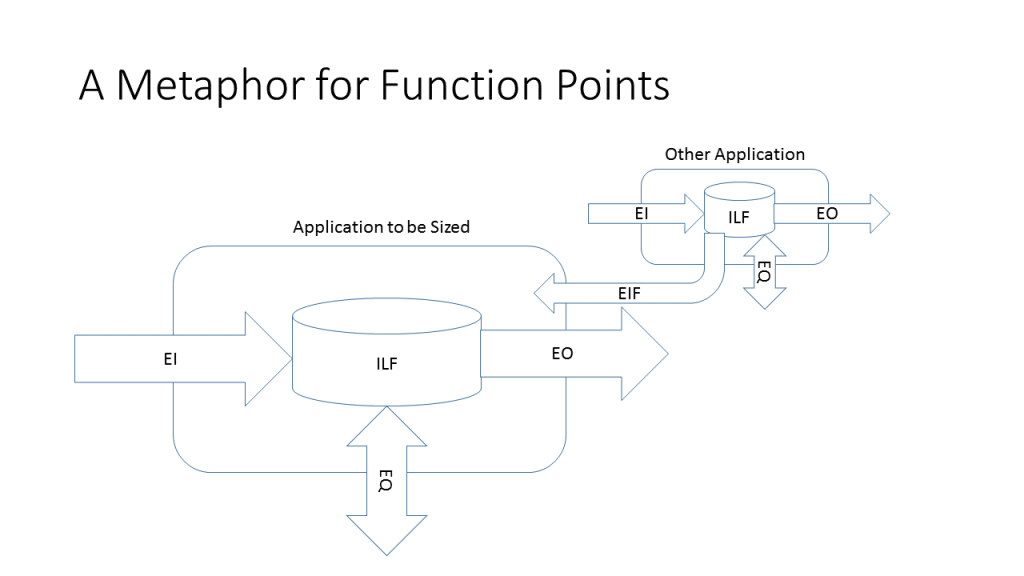
The diagram above and some of the ideas of this post are taken from A Very Short Course in Function Point Analysis. That post was intended to explain function point analysis. This one concentrates on the concepts and capabilities of the technique and how it fits into semi-classical estimating.
In the late Seventies, function points were developed by Allan Albrecht for IBM to estimate software development. IBM was developing systems in COBOL and PL/I. The same system might require a different number of lines of code depending on the programming language. Therefore, they wanted a measure that would be the same regardless of programming language. They developed function points. The function points measured both functional and non-functional requirements. In order to achieve vendor independence, the responsibility for function points was transferred to the International Function Point Users Group (IFPUG). Other versions of function points have come and gone. Some are still in use today. But the IFPUG version is the most commonly used. It is the variant being described here. The key to sizing in function points is to transform the application to be counted into the metaphor pictured above.
In order to transform the application to be sized into the metaphor above, take all of the parts of the application and distribute them into the data (Internal Logical Files and External Interface Files) and transactions (External Inputs, External Outputs and External Inquiries) shown above. These are some of the sub-stories described on the semi-classical estimating diagram. There is a many-to-many relationship between user stories and sub-stories. For example, suppose there was a user story that stated, “As a trader, I want to maintain a list of futures contracts that I am following.” This statement means that there is an Internal Logical File (ILF) called Futures. There should be three External Inputs (EIs), one each to add, change and delete information about a futures contract. There would also be an External Inquiry (EQ) to show what the input looked like before the change input. However, if there was a user story stating, “As a trader, I will get an error message if erroneous information is entered.” no new transaction is identified. It is part of the add, change and delete inputs that we already counted. All of the function point components can have 3 levels of complexity: low, average and high. The complexity is a function of the amount of data involved in the transaction. Each level of complexity has a different function point weight. It is often impossible to know how much data is involved in a transaction early in the life cycle. Fortunately, in semi-classical estimating, this complexity is estimated in other ways.
There are two types of data, or logical files, in the function point metaphor: ILFs and External Interface Files (EIFs). Looking at the metaphor at the top of the page tells most of the story. An ILF is a store of date in the application to be sized. The EIF is an ILF in some other application that the application to be sized accesses in a read-only fashion. Every EIF is someone else’s ILF. Some ILFs are someone else’s EIF. So now, what is an ILF? They are often the main physical files in an application. They are user identifiable. Early in the life cycle, they are the nouns that are in user stories. In the user story shown in the previous paragraph, Futures Contracts would probably be an ILF. The complexity of the data is a function of the number of data items and Record Element Types (RETs) that are in the logical file. RETs usually correspond to the other logical files that are related to a particular file. All of this is frequently unknowable early in the life cycle.
External Inputs (EIs) originate from outside of the application and cross the boundary. Usually, they write to one or more ILFs. The classic example is a transaction file that is processed by the application. It often is more than one transaction type in the file. For example, there might be a transaction to add a new entry into an ILF, another one to change the data in an existing entry in the ILF and one to delete entries. In this example, there is one physical transaction file, but three different EIs. EIs mostly deal with data. For example, some applications have menu screens that require the user to choose which screen to proceed to next. These are NOT EIs. They are not considered functionality at all.
Checking the metaphor shows that there are two way that data can leave the boundary of the application being counted: External Outputs (EOs) and External Inquiries (EQs). Why two? The EOs tend to be a little more complicated, and thus have more function point weight associated with them. We have not explained how to calculate the function points. This is explained in many places as well as being built into any tool that maintains function point counts. It is not that important to learn. In what ways are EOs more complicated. One possibility is that calculations are performed. Any report that has totals or calculates derived detail values is an EO, not an EQ. The other common complication is that an EO might update an ILF. For example, if there is a program that generates checks, and updates a file so that an interruption in check processing does not lead to duplicate checks being printed, then it is an EO, not an EQ. An EO may contain an input if it is part of the same elementary process. For example, if a screen accepts a social security number and displays pay check information along with year-to-date totals, then it is an EO, not an EI and an EO. Historically, EQs were intended to be simple outputs from an application. For example, if there was a screen that accepted a social security number, read employee information from an ILF and then displayed it without doing any calculations, then this was an EQ. This is still the case.
In semi-classical estimating, function point size is being estimated; not counted. There are three reasons for this. First, there is usually not enough known about the system to be built to do a function point count. The exact data elements have not, and will not, be specified until the application is being built. Second, attempting to do a exact count takes more time than it would be worth. The people involved in semi-classical estimating have more to do than just function point counting. In some cases they must perform some type of Software Non-functional Assessment Process (SNAP). In any case, they must also utilize estimating models to transform these software sizes into estimates of effort, staff size and schedule. They are often product owners or business analysts. They have to maintain backlogs of user stories, prioritize them, communicate with users and perform other non-estimating functions. Third, the people involved in semi-classical estimating often have not been trained in all of the nuances of function point analysis. They do not have to be. I came to understand this early in my career as an estimator.
Years ago, I worked for a major consulting firm doing estimating and work with software metrics. One of our offices was working on a proposal and wanted my help doing the estimate. I agreed to go out, but I could not get there for a few days. The analysts working on the proposal asked me to send them the IFPUG Counting Practices Manual. I did. I did not have high hopes. I was the only IFPUG Certified Function Point Specialist (CFPS) in our division. Capers Jones, a well known specialist in software engineering, had made the statement that a CFPS was required to count function points. When I got to the branch office, I immediately saw some errors in the count. I was afraid that it might be off by an order of magnitude. I spent the evening recounting. The situation was nowhere near as bad as I had feared. We had a difference of 25%. To put this in perspective, two CFPSs might disagree by as much as 10% and the counts would still be considered valid. If those analysts had any training, the discrepancy would have been less than the 25%. When the other dimensions of estimating and planning a release are considered, there is no reason to think that product owners cannot do an adequate job of applying semi-classical estimating after receiving a few days of training.
Leave a Reply