Some of the ideas of this post are taken from A Very Short Course in SNAP. That post was intended to explain the basics Software Non-functional Assessment Process (SNAP). This one concentrates on the concepts and capabilities of the technique and how it fits into semi-classical estimating.
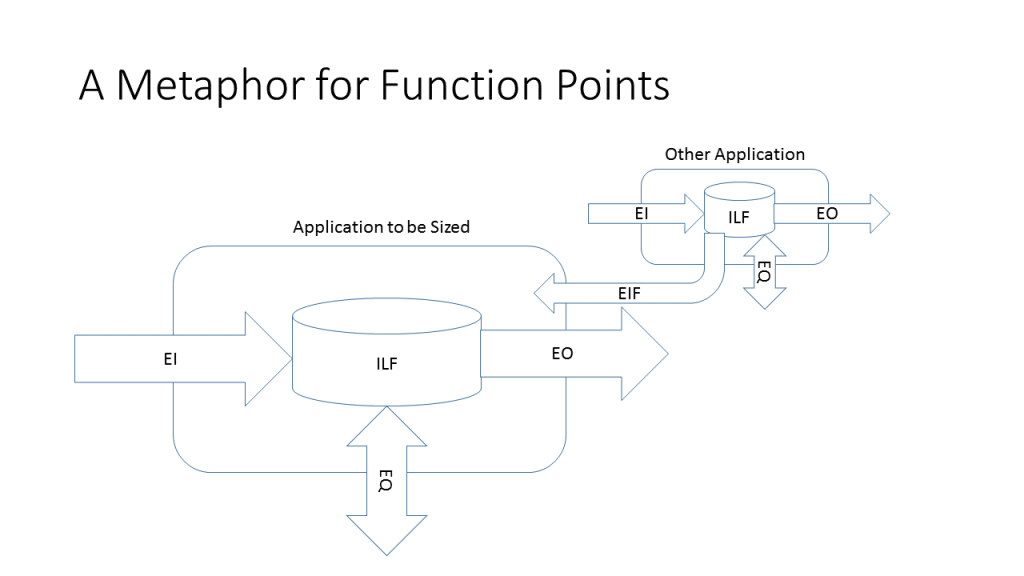
First, here is some historical perspectives. When Allan Albrecht developed function points, it sized both the functional and the technical aspects of a system. The functional aspects were described in Concepts and Capabilities of Function Point Estimating of Initial User Stories. Albrecht also identified 14 General Systems Characteristics (GSCs) that were scored with a value between 0 (not present or no impact) and 5 (had a great impact on system design). For example, the first GSC was Data Communications. A batch system would have a value of zero. The function point manual listed a variety of telecommunications protocols. If the application was “more than a front-end, and supports more than one type of teleprocessing communications protocol” then it had a value of 5. The GSCs were used to adjust the functional size. An application with 1,000 unadjusted function points would end up with an adjusted size somewhere between 650 and 1,350 function points, depending on the weights assigned to the GSCs.
From the beginning, there were some concerns about using the GSCs. It was felt that they did not allow an application’s size to be adjusted enough. For example, an application with extreme mathematical complexity would only be 5% larger than one that did not. From an estimating perspective, this did not seem to be sufficient. The other problem became obvious over time. The GSCs were based on computer technology from the Seventies. Many technical considerations, like which telecommunications protocols are being used, have been hidden from modern developers.
In 2007, the International Function Point Users Group (IFPUG) began work on the Technical Size Framework that would eventually become SNAP. In about 7 years, SNAP became a standard like the function point standard. A counting practices manual was produced, a class was created to teach SNAP and a certification exam was created so that people could be certified to do SNAP counts just like they could be certified to do function point counts. Function point counters produce function point counts; SNAP counters, SNAP counts. They are two different counts that measure two different dimensions of at an application’s size. Like a person’s height and weight, they are both measures of size. Like a person’s height and weight, it makes no sense to add them together. However, both function points and SNAP points impact an effort estimate in their own ways.
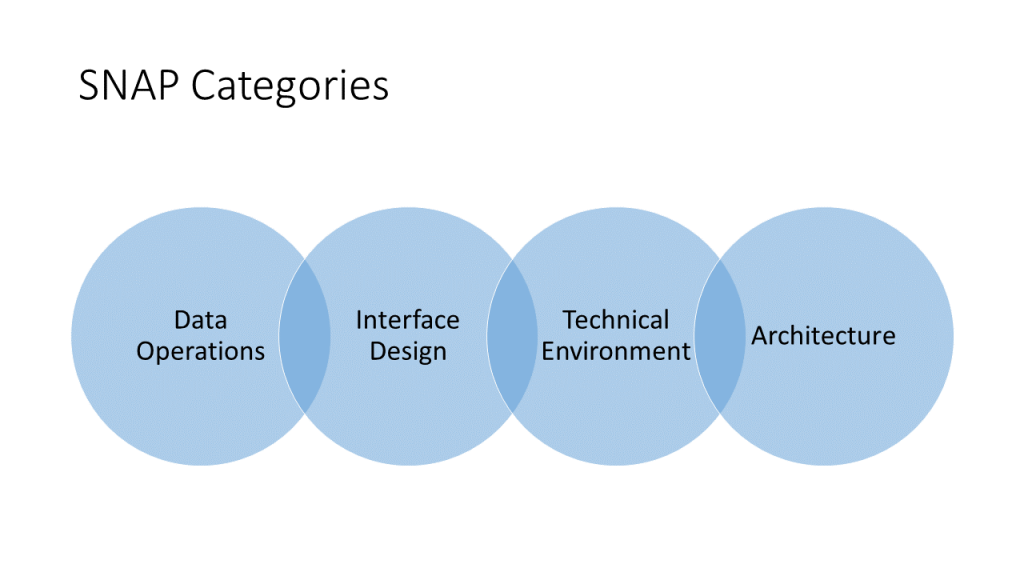
SNAP has four categories that are used to measure non-functional user requirements: Data Operations, Interface Design, Technical Environment and Architecture. Each of these have sub-categories that are used to perform the actual counts. To understand the concepts and capabilities, it is only necessary to get an idea of what the categories measure.
Data Operations measure some of the relative complexity of data manipulation that are not captured by functional measures. For example, the validation of data that is entered into the system is considered. So is the complexity of certain logical and mathematical operations. Data formatting is also considered. Function points are only concerned with data that crosses the automation boundary; here internal data movement is also considered. Some software applications are table driven to the extent that new capabilities can be added by adding new information to these tables. One of the sub-categories in data operations measures application changes made in this manner.
Interface Design considers graphical user interfaces, help subsystems and multiple I/O methods. Interface designs can make or break an application but do not involve a significant difference in functional size. A batch version of Facebook might have had the same function point count but would not have made Mark Zuckerberg nearly as rich. The usability of a user interface is measured here. Help subsystems take time to develop and maintain. This effort is considered in this SNAP category. There has been a question of how to measure the functionality of multiple input methods. For example, the same data might be input using either a smart phone or a web screen. Some organizations consider this a single External Input. For those organizations, SNAP provides a measure to account for this added complexity. The same is true for multiple output methods. An application might send the same information out as either a voice message or a text message. Some organizations might consider this a single External Inquiry. For those organizations, SNAP provides a measure to account for this added complexity.
Technical Environment considers multiple platforms, database technology and batch processes. A multi-platform application must work on more than one hardware or software platforms. The simplest case is when a web application must work with multiple browsers (Google Chrome, Firefox, Opera and Safari) on multiple operating systems (Windows, MacOS and Linux). There are more complicated scenarios. Database technology can involve changes to a database to achieve performance improvements without impacting the functionality of the application. When a process does not cause data to cross the application boundary, it is considered to have no functional significance. Many applications have “housekeeping” processes that may validate data, archive data and delete data that is no longer necessary. These usually reside in batch processes. These are measured as part of the Technical Environment.
Architecture considers component based software and multiple input / output interfaces. As the name implies, component based software measures the impact of using software components to build applications. It is not a functional consideration, but a technical one. It usually takes time to understand and properly use a software component. Software components may have been developed by the organization and used in another project or projects. They might have been acquired from a third party. They are both counted but the third party components are weighted higher. Multiple input / output interfaces sounds like something that was discussed under the Interface Design category. It is completely different. Sometimes, additional interfaces are added for performance reasons. This happens with blockchain mining applications. There are often situations where additional unique interfaces are added to an application, like when a organization’s partnership program adds a new participant. Here, there is no functional change because the interface is identical in format and logic. However, it may require additional implementation effort because some work may be done to job streams to accommodate this.
SNAP is designed to be used for both new development and enhancement projects. However, it is apparent that there are difficulties using it for new agile development projects. When initial user stories are written, they do not have the level of detail that SNAP utilizes. Most of the Data Operations require that all of the fields have been identified. Obviously, the same is true of Interface Design. The decisions that drive the Technical Environment and Architecture categories are often not made until the first few iterations, or sprints, of development.
On the other hand, SNAP shines when evaluating changes to systems. Enhancement projects contain these changes. In fact, agile development is characterized by the quick development of small releases. Only the first is truly new development. All subsequent releases usually have some new functionality and some changed functionality.
In 2016, Anandi Hira and Barry Boehm addressed the 10th ACM/IEEE International Symposium on Empirical Software Engineering and Measurement. They described research they had done involving both function points and SNAP points. They measured both function points and SNAP points for projects that they were adding functionality to and changing the functionality of the University of Southern California’s (USC’s) Unified Code Count (UCC) tool. When new functionality was being added to the tool, the function point were a good predictor of effort. Using SNAP in addition to the function points made a minor improvement to the effort predictions. For changed functionality, SNAP alone was the best predictor of effort.
This explains how the sizing principles of semi-classical estimating were established. New functionality is sized with estimated function points. Estimated function points are less precise than counted function points. Usually, there is not enough details known to count function points or SNAP points anyway. Both technical and functional changes are sized with Enriched SNAP points. Technical changes are what SNAP was designed to measure. Functional changes can be tricky. At one extreme there are small changes that everyone agrees are functional. For example, if the decision is made to capture customer’s birthdays in an existing customer entry screen that does not currently capture it. This is a functional change and would have been sized by giving function point credit equal to the size of the new screen. In semi-classical estimating, this would be sized by using one of the Data Operations subcategories. There are other situations that an organization can elect to treat as either a functional change or a technical one. For example, when some organizations treat multi-media outputs as separate functional transactions and others treat them a single functional transaction. In the latter case, they SNAP is used for the other occurrences. In semi-classical estimating, SNAP is always used to measure the size of additional outputs of different media or changes to any of the outputs. Thus, in semi-classical estimating, SNAP becomes the default size measure when changes are made to an application. This is why the measure is referred to as Enriched SNAP points. It will measure a few things in addition to the ones that are in a traditional SNAP measurement.