When I was going to college and even when I first graduated, I used to work with my father doing roofing. One day he told me to flash the skylight on a roof we were working on. (If you don’t know what this means, don’t worry about it.) My father joking said, “I’ve been a roofer for 30 years as man and boy, and you expect me to just tell you about roofing?” I shrugged. He continued, “Don’t worry. If you have 15 minutes I will explain everything you need to know.” That is the spirit of this post. I do not want to slight either roofers or function point counters. if you are a function point counter or even an estimator who works with function points, you probably do not need to read this post at all. However, if you are an analyst, product manager, agile developer, this post should teach you what you need to know about function points in order to proceed with agile estimating.
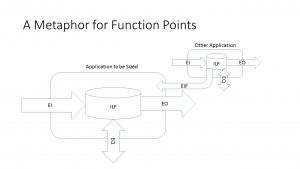
Originally, function points were developed for estimating software development. IBM was developing systems in COBOL and PL/I. The same system might require a different number of lines of code depending on the programming language. Therefore, they wanted a measure that would be the same regardless of programming language. They developed function points. The function points measured both functional and non-functional requirements. In order to achieve vendor independence, the responsibility for function points was transferred to the International Function Point Users Group (IFPUG). Other versions of function points have come and gone. Some are still in use today. But the IFPUG version is the most commonly used. It is the variant being described here. The key to sizing in function points is to transform the application to be counted into the metaphor pictured above. It probably involves a couple of hundred rules, but only the most commonly used ones will be discussed below.
Boundary and scope are a concern when function point counting. What if an application is multi-tiered, i.e. what if some of it is implemented on a mainframe and some on a phone? Are they separate applications? Counters would say no, there is one boundary. Estimators should say the same thing, even if the work is being performed by two separate teams. Breaking up the development would ignore the communications overhead between the two teams. It would understate the effort and schedule of the total project. Are there times when counters and estimators might disagree regarding the boundary. Yes, conversion work is often such a case. For example, suppose a new version of a legacy system is being developed. As part of this effort, the existing data must be converted and loaded into the new application. Function point counters would say that each logical file that receives a load of converted data would be an external input into the new application. The conversion is a one-time job, so it is part of the project, but it does not become part of the application. Estimators often break the conversion work into a separate project with a separate boundary. It may end up with a good deal of data cleaning and other activities not considered in the function point counting scenario. An estimator should use the function point counters approach unless doing otherwise would deliver a better estimate.
The key to transforming the application to be sized into the metaphor above is to take all of the parts of the application and distribute them into the data (Internal Logical Files and External Interface Files) and transactions (External Inputs, External Outputs and External Inquiries) shown above. This can be done with externals like screens and reports or with user stories early in the life cycle. In any case, there is a many-to-many relationship between the application components and the functional components. For example, suppose there was a user story that stated, “As a trader, I want to maintain a list of futures contracts that I am following.” This statement means that there is an Internal Logical File (ILF) called Futures. There should be three External Inputs (EIs), one each to add, change and delete information about a futures contract. There would also be an External Inquiry (EQ) to show what the input looked like before the change input. However, if there was a user story stating, “As a trader, I will get an error message if erroneous information is entered.” no new transaction is identified. It is part of the add, change and delete inputs that we already counted. All of the function point components can have 3 levels of complexity: low, average and high. The complexity is a function of the amount of data involved in the transaction. Each level of complexity has a different function point weight. It is often impossible to know how much data is involved in a transaction early in the life cycle. It is unnecessary to know how to calculate the number of function points at this time.
There are two types of data, or logical files, in the function point metaphor: ILFs and External Interface Files (EIFs). Looking at the metaphor at the top of the page tells most of the story. An ILF is a store of date in the application to be sized. The EIF is an ILF in some other application that the application to be sized accesses in a read-only fashion. Every EIF is someone else’s ILF. Some ILFs are some else’s EIF. So now, what is an ILF? They are often the main physical files in an application. They are user identifiable. Early in the life cycle, they are the nouns that are in user stories. In the user story shown in the previous paragraph, Futures Contracts would probably be an ILF. The complexity of the data is a function of the number of data items and Record Element Types (RETs) that are in the logical file. RETs usually correspond to the other logical files that are related to a particular file. All of this is frequently unknowable early in the life cycle.
Transactions are External Inputs (EIs), External Outputs (EOs) and External Inquiries (EQs). They have a quite a few attributes in common. For one thing, they all cross the application boundary. If there is a batch process that reads from one ILF and updates another, then this is not a functional transaction. It is not counted using function points. They are all elementary processes. Information engineering defined an elementary process as the smallest process that was of interest to the business. Elementary processes are best explained with examples that will be given below when each of the transaction types are elaborated on. Finally, they are unique. If the same report is sent to a trader and another account owner, it is one EO, not two. The bad news is that elementary processes and uniqueness can sometimes be complicated topics for function point counters; the good news is that most of the cases will fall into a reasonably small set of patterns that an estimator can determine. The complexity of a transaction is determined by the number of data items involved as well as the number of File Types Referenced (FTRs). FTRs is simply the number of ILFs and EIFs that the transaction interacts with. You guessed it; this information is frequently unknowable early in the life cycle.
External Inputs (EIs) originate from outside of the application and cross the boundary. Usually, they write to one or more ILFs. The classic example is a transaction file that is processed by the application. It often is more than one transaction type in the file. For example, there might be a transaction to add a new entry into an ILF, another one to change the data in an existing entry in the ILF and one to delete entries. In this example, there is one physical transaction file, but three different EIs. Everything that was just said about transaction files also applies to screens. A maintenance screen will often have separate EIs for add, change and delete functions. Function points are also applicable to real time. A typical EI might be input from a thermostat or a bar code reader. EIs mostly deal with data. For example, some applications have menu screens that require the user to choose which screen to proceed to next. These are NOT EIs. They are not considered functionality at all.
Checking the metaphor shows that there are two way that data can leave the boundary of the application being counted: External Outputs (EOs) and External Inquiries (EQs). Why two? The EOs tend to be a little more complicated, and thus have more function point weight associated with them. We have not explained how to calculate the function points. This is explained in many places as well as being built into any tool that maintains function point counts. It is not that important to learn. In what ways are EOs more complicated. One possibility is that calculations are performed. Any report that has totals or calculates derived detail values is an EO, not an EQ. The other common complication is that an EO might update an ILF. For example, if there is a program that generates checks, and updates a file so that an interruption in check processing does not lead to duplicate checks being printed, then it is an EO, not an EQ. An EO may contain an input if it is part of the same elementary process. For example, if a screen accepts a social security number and displays pay check information along with year-to-date totals, then it is an EO, not an EI and an EO.
Historically, EQs were intended to be simple outputs from an application. For example, if there was a screen that accepted a social security number, read pay check information from an ILF and then displayed it without doing any calculations, then this was an EQ. This is still the case. However, now an EQ is anything that presents information from an ILF without updating an ILF or performing calculations. Screen drop downs that read from ILFs are EQs, but only counted once per application, not once per screen where they are used. A report that does not require any calculations or update any ILFs is an EQ, not an EO. Emails or messages that exit an application may be EOs or EQs, depending upon whether they present calculations or update ILFs. However, if they are error messages, they are neither. Error messages are considered to be part of the EI that raised the error. There is a fundamental difference between EIs and EOs/EQs. If I have an input file with adds, changes and deletes, then there will be 3 EIs. However, if I generate a transaction file in my application with adds, changes and deletes, it is a single EO or EQ.
For completeness, we have to cover the Value Adjustment Factor. When function points were invented, it was understood that you needed to consider non-functional requirements in order to estimate. Everything above had to do with what the application was intended to do. How it would do in it was the technical or non-functional considers. 14 general systems characteristics were identified. These considered topics like backup and recovery, various forms of complexity including logical and mathematical, features to facilitate end user efficiency and more. However, the industry has decided that they did not cover enough. Estimating tools like COCOMO II use function points without the VAF, along with their own cost drivers to take the place of the VAF. IFPUG had created a Software Non-functional Assessment Process (SNAP) to take the place of the VAF. A few people have argued that calculating the VAF is a way to compare new projects to historical ones that were counted using it. For agile estimators, the VAF is best forgotten!
Leave a Reply